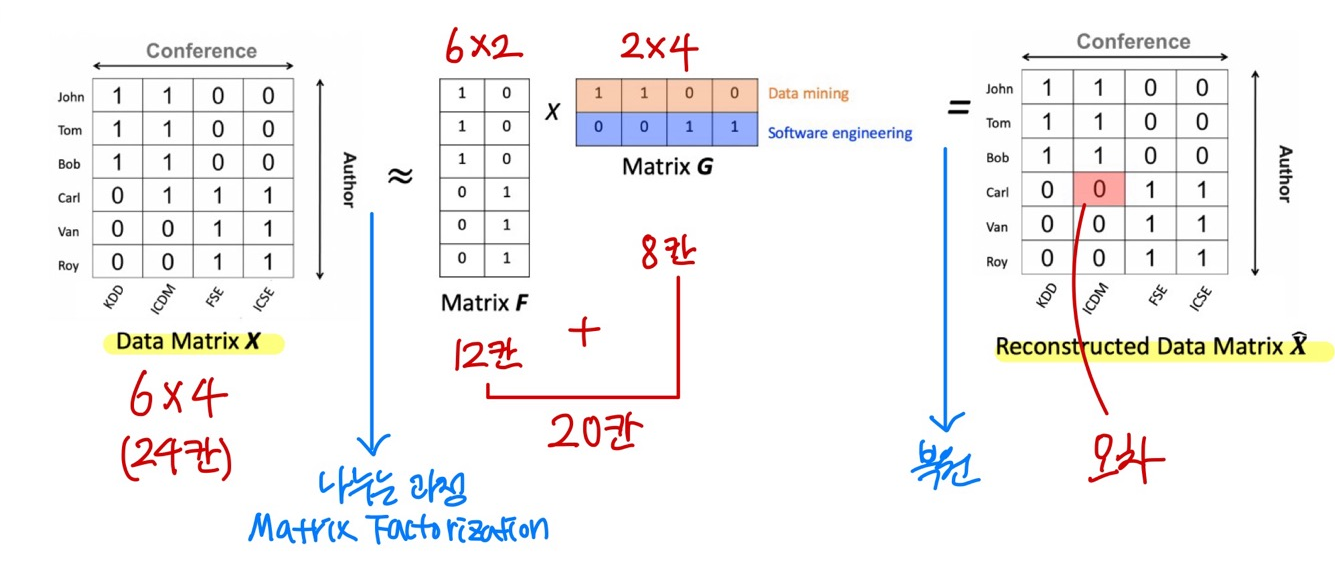
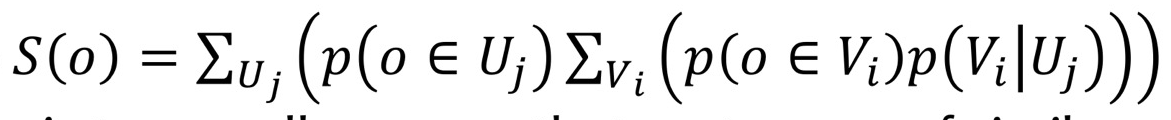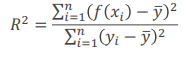1. Basic concept - outlier은 normal한 패턴을 따르지 않는 것 2. Statiscal approaches: 통계적 기법으로 outlier 찾기(box plot, normal distribution, t-distribution, distance-based, realistic k로 local outlier)3. Proximity-based approaches4. Reconstruction-based approaches - normal한 방법을 대표하는 모델 (succint represention)으로 복원시켰을 때, normal한 것은 모델을 따르고, outlier은 모델을 따르지 않음.5. Clustering and Classification based approaches - 클러..