1. Basic concept
2. Statiscal approaches
3. Proximity-based approaches
4. Reconstruction-based approaches
- Matrix factorization based method
5. Clustering and Classification based approaches
- Clustering-based approaches
- Classification-based approaches
6. Mining contextual and collective outliers
7. Outlier detection in high-dimensional data
<Reconstruction-Based Approaches: 예시>
- 어떠한 data를 설명하기 위한 model(Succinct representation)을 오차를 최소화 하도록 매우 잘 만들고, model로 data를 재현해봄.
- normal data는 압축이 잘 되고, 압축된 표현에서 원본 데이터로 정확히 복원할 수 있지만 이상치는 그렇지 않음.
- Succinct representation로 재현한 data를 origianl과 비교했을 때, 비슷하거나 다른 것이 있을 것.
- 재현한 data 중 original과 매우 다른 것 (복원 오류): outlier로 간주
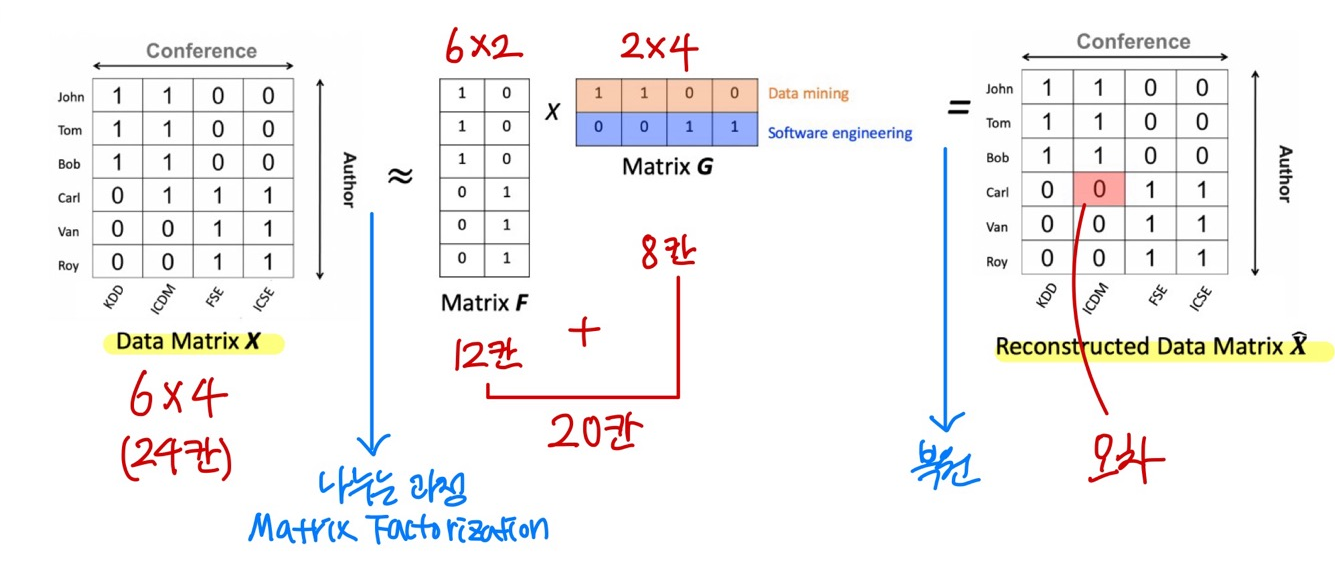
<Matrix Factorization Based Method (with Numeric data)>
- 매우 핫한 방법
- original data: 3행 4열 data (칸 12개)
| 백 | 유 | 김 | 박 | |
| A에서 논문 썼는가? | 0 | 0 | 1 | 0 |
| B에서 논문 썼는가? | 1 | 0 | 1 | 1 |
| C에서 논문 썼는가? | 1 | 1 | 0 | 0 |
- original data를 matrix factorization으로 압축할 것이다.
- 3*4 matrix → 3*1 matrix(3칸) * 1*4 matrix(4칸)으로 나누는 것: matrix factorization
- 12칸 → 7칸으로 5칸 절약함.
- 5칸을 잘 채워야 오차 줄일 수 있음. (딥러닝 사용하여 채움)
- factorization 복원 후 original과 비교하고, error을 기록한 후 가장 error가 큰(threshold를 넘은) 것을 outlier라고 정의.
- 추천 시스템에서는 결측치에 대한 예측으로 사용
- 원본 데이터 (history) 결측치가 있을 때, 압축을 한 다음에 복원을 하면 모델이 결측치를 채움(예측)
- 복원한 데이터에는 결측치가 존재하지 않음. 채워진 결측치를 통해 추천 진행

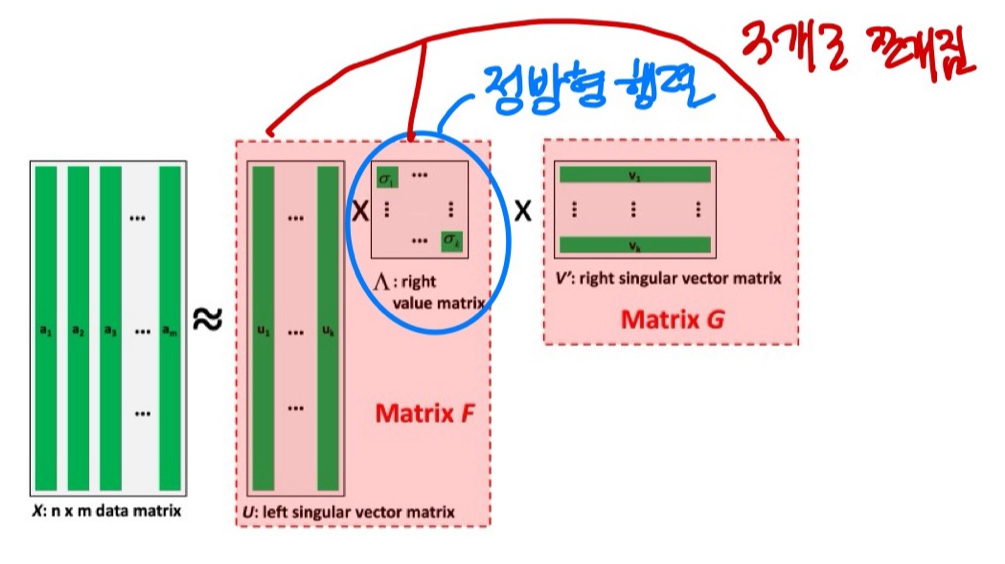
<Single Value Decomposition(SVD)>
- 6*4 → 6*2 x 2*2 x 2*4 3개의 matrix로 나눔.
중간에 정방형 matrix 하나 끼워넣으면 모델의 성능을 높일 수 있을 것. model의 size가 커졌으므로 - if original에 결측치 있을 때: 딥러닝을 통해 weight 채워넣음(예측을 위한 결측치 계산)
- categorical data에서는 어려움
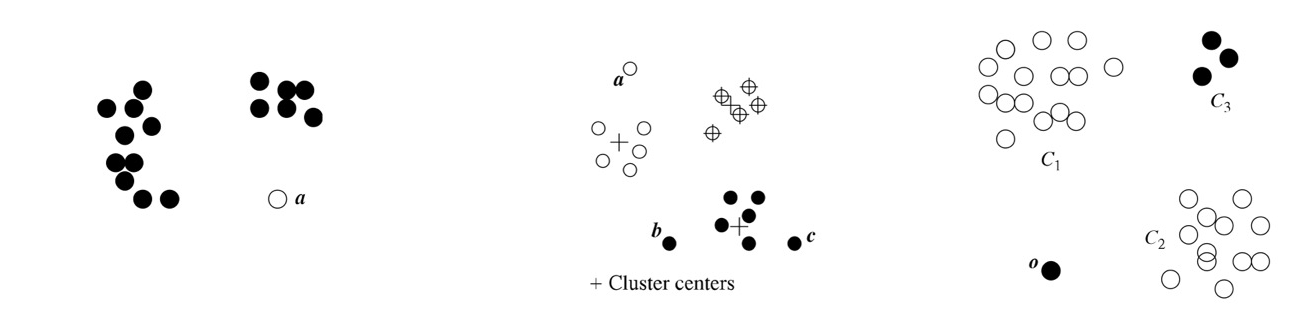
<Three Clustering-based Outlier Detection Approaches>
- object가 어느 cluster에도 속해있지 않다면 → outlier이다.
- object와 object와 가장 가까운 cluster 사이의 거리가 매우 크다면 → outlier 이다.(애매)
- object가 small or sparse한 cluster의 일부라면(cluster가 너무 작으면) → cluster의 모든 objects는 outlier 이다.
<Classification-Based Approaches>
- Labeling이 붙어져 있는 Supervised learning
- outlier인지 normal인지 labeling 되어져 있는 data 필요
- 구분 가능하도록 학습한 classifier가 normal이라고 하면 normal data, outlier면 outlier.
- 어려움: 일반적으로 data는 치우쳐져 있음. unbalanced (normal이 매우 많고, outlier는 극소수)
→ unbalanced한 data에 맞는 classification을 써야 함. (나중에 분류 배울 때)
'공부 > 데이터 마이닝' 카테고리의 다른 글
| [데이터 마이닝] Ch.11 - Contextual and Collective outliers를 Mining하기, 고차원 데이터에서 Outlier Detection (0) | 2024.12.04 |
|---|---|
| [데이터 마이닝] Ch11. Outliers - Statiscal, Proximity-based outlier detection (0) | 2024.12.01 |
| [데이터 마이닝] Ch11. Outlier - Basic concept (0) | 2024.12.01 |
| [데이터 마이닝] Ch8. Cluster analysis - Density-based/Grid-based (0) | 2024.11.20 |
| [데이터 마이닝] Ch8. Cluster analysis -Hierarchical methods (0) | 2024.11.20 |